Today's generative models are capable of synthesizing high-fidelity images, but each model specializes on a specific target domain. This raises the need for model merging: combining two or more pretrained generative models into a single unified one. In this work we tackle the problem of model merging, given two constraints that often come up in the real world: (1) no access to the original training data, and (2) without increasing the size of the neural network. To the best of our knowledge, model merging under these constraints has not been studied thus far.
We propose a novel, two-stage solution. In the first stage, we transform the weights of all the models to the same parameter space by a technique we term model rooting. In the second stage, we merge the rooted models by averaging their weights and fine-tuning them for each specific domain, using only data generated by the original trained models. We demonstrate that our approach is superior to baseline methods and to existing transfer learning techniques, and investigate several applications.
Generative adversarial networks (GANs) have achieved impressive results in neural image synthesis. However, these generative models typically specialize on a specific image domain, such as human faces, kitchens, or landscapes. This is in contrary to traditional computer graphics, where a general purpose representation (e.g., textured meshes) and a general purpose renderer can produce images of diverse object types and scenes. In order to extend the applicability and versatility of neural image synthesis, in this work we explore model merging - the process of combining two or more generative models into a single conditional model.
A problem arises when one wants to use several pre-trained generators for semantic manipulations (e.g., interpolating between images from GAN A and GAN B) - the different models do not share the same latent representation, and hence do not "speak the same language". Model merging places several GANs in a shared latent space, allowing such cross-domain semantic manipulations.
We tackle the problem of merging several GAN models into a single one under the following real-world constraints:
One way to combine several neural networks is by performing some arithmetic operations on their parameters. For example, Exponential Moving Average (EMA) is a technique for averaging the model weights during the training process in order to merge several versions of the same model (from different checkpoints during the training process).
A key feature in the EMA case is that the averaging is performed on the same model from different training stages. Thus, we can say that the averaging is done on models that share the same common ancestor model, and we hypothesize that this property is key to the success of the merging procedure.
Inspired by this observation, we propose to start the merging process by first perform a model rooting - converting all the models to be in the same weights semantic space by fine-tuning, and only them perform the merging by and additional fine-tuning. The effectiveness of the rooting stage can be even seen visually as depicted in the following figure:

For more details please read the paper.
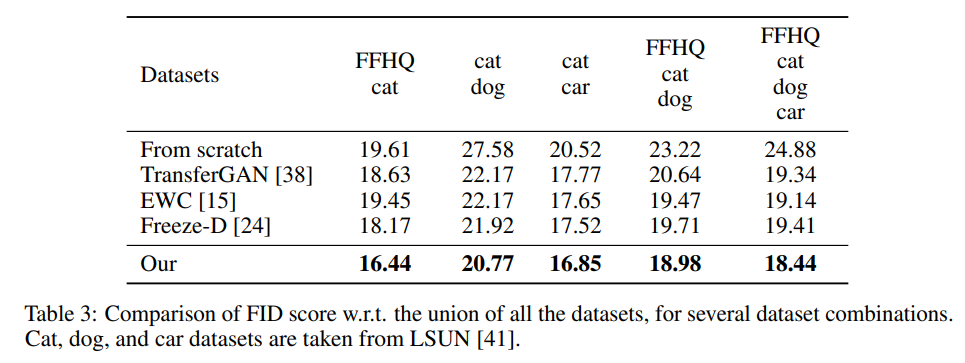
We compared our method to other SOTA methods and found that under all the training datasets our method outperformed the baselines:
Merging several pre-trained GANs into a shared latent embedding space can be beneficial for many applications. For example:
The shared latent space can be leveraged in order to perform latent space Interpolation between images of different modalities.

When using special GAN architectures that encourage disentanglement properties, such as StyleGAN, we can perform style mixing between images of different modalities.

We can calculate the semantic direction in the latent space by taking the direction of the normal to the hyperplane calculated by SVM and going along this direction.
If we can find the desired labels easily on only one of the modalities (e.g., we have a human face orientation classifier), we can calculate the direction using only samples from this domain, and apply it to the other domain (because of the shared latent embedding space).

If you find this research useful, please cite the following:
@inproceedings{avrahami2022gan,
title={Gan cocktail: mixing gans without dataset access},
author={Avrahami, Omri and Lischinski, Dani and Fried, Ohad},
booktitle={European Conference on Computer Vision},
pages={205--221},
year={2022},
organization={Springer}
}