Aleph: A new way to edit, transform and generate video
Runway, 2025
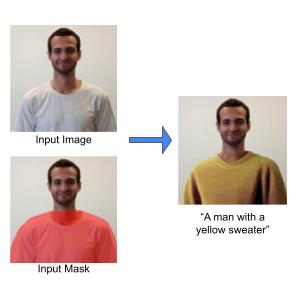
Runway Aleph is a state-of-the-art in-context video model, setting a new frontier for multi-task visual generation, with the ability to perform a wide range of edits on an input video such as adding, removing, and transforming objects, generating any angle of a scene, and modifying style and lighting, among many other tasks.