Method
We aim to provide the user with more fine-grained control over the generated image. In addition to a single global text prompt, the user will also provide a segmentation map, where the content of each segment of interest is described using a local free-form text prompt.
However, current large-scale text-to-image datasets cannot be used for this task because they do not contain local text descriptions for each segment in the images. Hence, we need to develop a way to extract the objects in the image along with their textual description. To this end, we opt to use a pre-trained panoptic segmentation model along with a CLIP model.
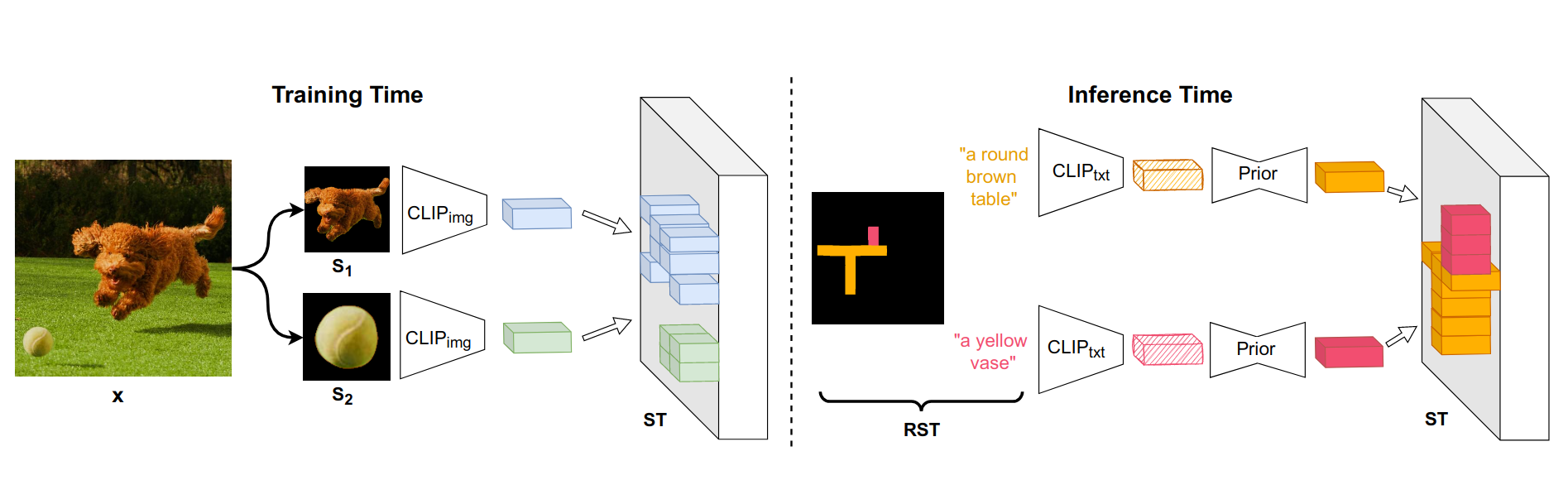
During training (left) - given a training image x, we extract K random segments, pre-process them and extract their CLIP image embeddings. Then we stack these embeddings in the same shapes of the segments to form the spatio-textual representation ST. During inference (right) - we embed the local prompts into the CLIP text embedding space, then convert them using the prior model P to the CLIP image embeddings space, lastly, we stack them in the same shapes of the inputs masks to form the spatio-textual representation ST.