The tremendous progress in neural image generation, coupled with the emergence of seemingly omnipotent vision-language models has finally enabled text-based interfaces for creating and editing images. Handling generic images requires a diverse underlying generative model, hence the latest works utilize diffusion models, which were shown to surpass GANs in terms of diversity. One major drawback of diffusion models, however, is their relatively slow inference time. In this paper, we present an accelerated solution to the task of local text-driven editing of generic images, where the desired edits are confined to a user-provided mask. Our solution leverages a recent text-to-image Latent Diffusion Model (LDM), which speeds up diffusion by operating in a lower-dimensional latent space. We first convert the LDM into a local image editor by incorporating Blended Diffusion into it. Next we propose an optimization-based solution for the inherent inability of this LDM to accurately reconstruct images. Finally, we address the scenario of performing local edits using thin masks. We evaluate our method against the available baselines both qualitatively and quantitatively and demonstrate that in addition to being faster, our method achieves better precision than the baselines while mitigating some of their artifacts.
Blended Latent Diffusion aims to offer a solution for the task of local text-driven editing of generic images that was introduced in Blended Diffusion paper. Blended Diffusion suffered from a slow inference time (getting a good result requires about 25 minutes on a single GPU) and pixel-level artifacts.
In order to address these issues, we offer to incorporate Blended Diffusion into the text-to-image Latent Diffusion Model. In order to do so, we operate on the latent space and repeatedly blend the foreground and the background parts in this latent space, as the diffusion progresses in the following way:
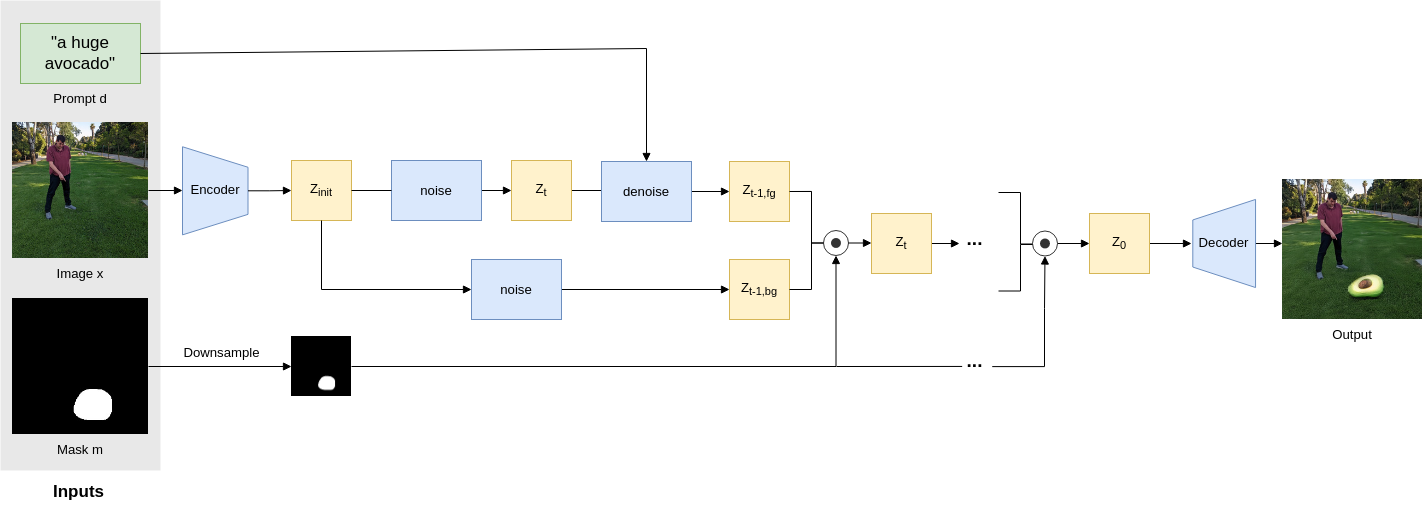
Operating on the latent space indeed enjoys a fast inference speed, however, it suffers from an imperfect reconstruction of the unmasked area and it is unable to handle thin masks. For more details on how we addressed these problems please read the paper.
Given a source image and a mask of the background, Blended Latent Diffusion is able to replace the background according to the text description. Note that the famous landmarks are not meant to accurately appear in the new background but serve as an inspiration for the image completion.

Input image

Input mask

"beach"

"big mountain"

"The Great Pyramid of Giza"

"Acropolis"

"Arc de Triomphe"

"big waterfall"

"China"

"Colosseum"

"fire"

"Golden Gate Bridge"

"Machu Picchu"

"Mount Fuji"

"New York City"
"nuclear power plant"

"Petra"

"rainy"

"river"

"Stanford University"

"Stonehenge"

"sunny"

"sunrise"

"swimming pool"

"volcanic eruption"

"winter"

"green hills"

"desert"

"big lake"

"forest"

"dusty road"

"horses stable"

"houses"
Given a source image and a mask of an area to edit, Blended Latent Diffusion is able to add a new object in the masked area seamlessly.

Input image

Input mask

"gravestone"

"toy truck"

"snake"

"big stone"

"bread"

"Buddha"

"car tire"

"clay pot"

"cola"

"egg"

"glow stick"

"ice cube"

"lamp"

"milk"

"pile of dirt"

"pile of gold"

"tooth"

"black chair"

"white chair"

"bonfire"

"stones"

"black stones"

"green stones"

"purple stones"

"red ball"

"yellow ball"

"huge ant"

"smoke"

"toy car"

"water puddle"

"huge apple"

"yellow toy truck"
Given a source image and a mask of an area to edit an existing object, Blended Latent Diffusion is able alter the object seamlessly.

Input image

Input mask

"a man with a yellow sweater"

"a muscular man with a blue shirt"

"a man with a red suit"
Blended Latent Diffusion is able to generate plausible texts.

Input image

Input mask

a horror book named "CVPR"

a children's book titled "ECCV"

a romantic novel titled "SIGGRAPH"
Because of the one-to-many nature of our problem, there is a need for multiple predictions for each input. Blended Latent Diffusion is able to to do so.

Input image

Input mask

Prediction 1

Prediction 2

Prediction 3

Prediction 4

Prediction 5

Prediction 6

Input image

Input mask

Prediction 1

Prediction 2

Prediction 3

Prediction 4
A user-provided scribble can be used as a guide. Specifically, the user can scribble a rough shape on a background image, provide a mask (covering the scribble) to indicate the area that is allowed to change, and provide a text prompt.Blended Latent Diffusion transforms the scribble into a natural object while attempting to match the prompt.

Input image

Input image with scribble

Input mask

Prediction 1

Prediction 2

Prediction 3
If you find this research useful, please cite the following:
@article{avrahami2023blendedlatent,
author = {Avrahami, Omri and Fried, Ohad and Lischinski, Dani},
title = {Blended Latent Diffusion},
year = {2023},
issue_date = {August 2023},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {42},
number = {4},
issn = {0730-0301},
url = {https://doi.org/10.1145/3592450},
doi = {10.1145/3592450},
journal = {ACM Trans. Graph.},
month = {jul},
articleno = {149},
numpages = {11},
keywords = {zero-shot text-driven local image editing}
}
@InProceedings{Avrahami_2022_CVPR,
author = {Avrahami, Omri and Lischinski, Dani and Fried, Ohad},
title = {Blended Diffusion for Text-Driven Editing of Natural Images},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {18208-18218}
}
