Natural language offers a highly intuitive interface for image editing. In this paper, we introduce the first solution for performing local (region-based) edits in generic natural images, based on a natural language description along with an ROI mask.
We achieve our goal by leveraging and combining a pretrained language-image model (CLIP), to steer the edit towards a user-provided text prompt, with a denoising diffusion probabilistic model (DDPM) to generate natural-looking results.
To seamlessly fuse the edited region with the unchanged parts of the image, we spatially blend noised versions of the input image with the local text-guided diffusion latent at a progression of noise levels. In addition, we show that adding augmentations to the diffusion process mitigates adversarial results. We compare against several baselines and related methods, both qualitatively and quantitatively, and show that our method outperforms these solutions in terms of overall realism, ability to preserve the background and matching the text. Finally, we show several text-driven editing applications, including adding a new object to an image, removing/replacing/altering existing objects, background replacement, and image extrapolation.
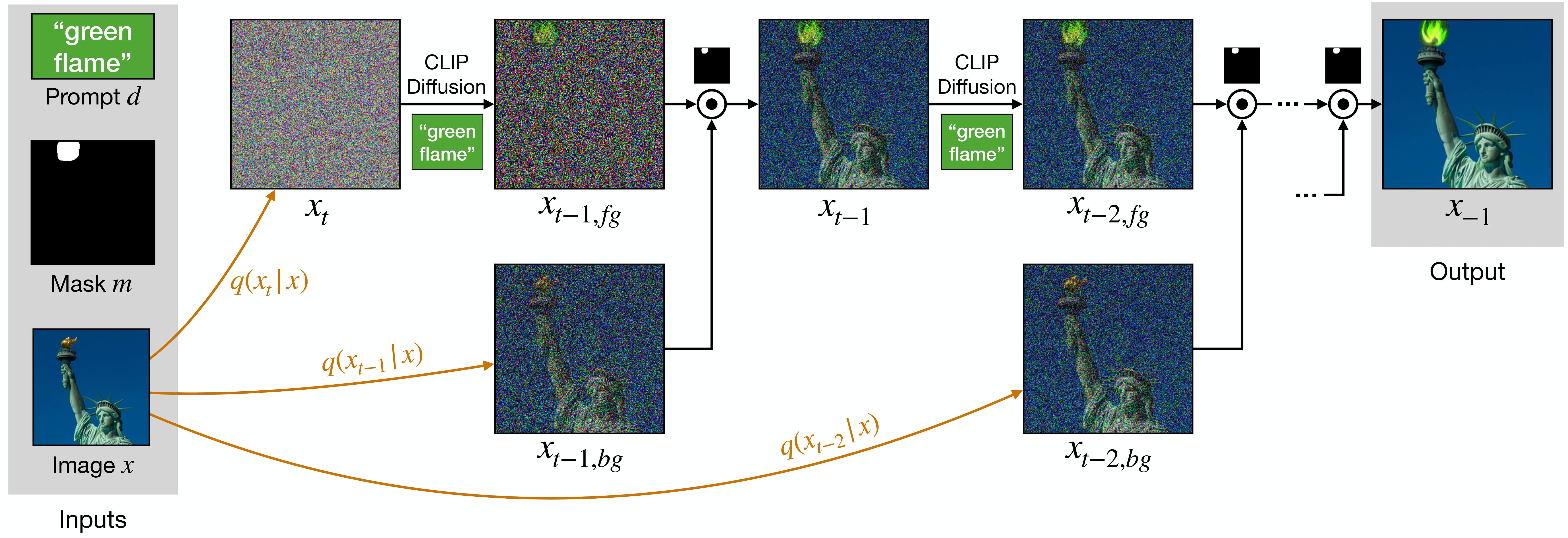
In a nutshell, Blended Diffusion utilizes CLIP model to manipulate the diffusion process of a pre-trained ImageNet diffusion model. The forward noising process implicitly defines a progression of image manifolds, where each manifold consists of noisier images. Each step of the reverse, denoising diffusion process, projects a noisy image onto the next, less noisy, manifold.
The key insight is that in order to create a seamless result we spatially blend each of the noisy CLIP-generated images progressively with the corresponding noisy version of the input image. While each of these blends is not guaranteed to be coherent, the projection to the next manifold makes it more coherent.
For more details please read the paper.
Given an input image and a mask, we demonstrate inpainting of the masked region using different guiding texts. When no prompt is given, the result is similar to traditional image inpainting.

Input image

Input mask

No prompt

"white ball"

"bowl of water"

"stool"

"hole"

"red brick"

"pile of dirt"

"laptop"

"plastic bag"

"rat"

"bonfire"

"snake"

"spider"

"plant"

"candle"

"blanket"

"bottle"

"cardboard"

"chocolate"

"clay pot"

"egg"

"flower"

"glass"

"glow stick"

"gravestone"

"helmet"

"milk"

"smoke"

Input image

Input mask

"car tire"

"big stone"

"meat"

"tofu"

"grass"

"blue ball"

"silver brick"

"ice cube"

"plastic bag"

"bowl of water"

"black rock"

"cardboard"

"tooth"

"water bottle"

"bread"

"smoke"

"chocolate"

"clay pot"

"cola"

"egg"

"flower"

"glass"

"glow stick"

"gravestone"

"helmet"

"lamp"

"milk"

"hole"
Because our problem is one-to-many by its nature, it is desirable to generate multiple plausible results for the same input prompt. Given an input image and a mask, and an input text prompt, Blended Diffusion is able to generate multiple plausible results.

Input image

Input mask

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Input image

Input mask

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction
Given an input image and a mask, Blended Diffusion is able to alter the foreground object corresponding to the guiding text.

Input image

Input mask

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction

Prediction
Given a source image and a mask of the background, Blended Diffusion is able to replace the background according to the text description. Note that the famous landmarks are not meant to accurately appear in the new background, but serve as an inspiration for the image completion.

Input image

Input mask

"big mountain"

"swimming pool"

"big wall"

"New York City"

"green hills"

"red house"

"oasis"

"Acropolis"

"fire"

"big waterfall"

"China"

"Colloseum"

"festival"

"Golden Gate Bridge"

"Machu Picchu"

"Mount Fuji"

"Petra"

"The Great Pyramid of Giza"

"river"

"snowy mountain"

"Stanford University"

"Stonehenge"

"sunrise"

"rainy"

"volcanic eruption"

"The Western Wall"

"Arc de Triomphe"

"big ship"

Input image

Input mask

"Acropolis"

"fire"

"China"

"Colosseum"

"Desert"

"festival"

"Grand Canyon"

"Machu Picchu"

"north pole"

"parking lot"

"Petra"

"river"

"snowy mountain"

"Stanford University"

"Stonehenge"

"rainy"

"volcanic eruption"

"The Western Wall"

"in the woods"

"beach"

"big waterfall"

"flower field"

"green hills"

"lake"

"oasis"

"book cover"

"fog"

"gravel"
Users scribble a rough shape of the object they want to insert, mark the edited area, and provide a guiding text. Blended Diffusion uses the scribble as a general shape and color reference, transforming it to match the guiding text. Note that the scribble patterns can also change. In the last example, we embedded a clip art of a table instead of a manual scribble, it shows the effectiveness of our model to transform unnatural clip arts into real-looking objects.

Input image

Input image + scribble

Input mask

Prediction

Prediction

Prediction
Input image
Input image + scribble
Input mask
Prediction
Prediction
Prediction

Input image

Input image + scribble

Input mask

Prediction

Prediction

Prediction

Input image

Input image + scribble

Input mask

Prediction

Prediction

Prediction
The user provides an input image and two text descriptions: "hell" and "heaven". Blended Diffusion extrapolates the image to the left using the "hell" prompt and to the right using the "heaven" prompt.

If you find this research useful, please cite the following:
@InProceedings{Avrahami_2022_CVPR,
author = {Avrahami, Omri and Lischinski, Dani and Fried, Ohad},
title = {Blended Diffusion for Text-Driven Editing of Natural Images},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {18208-18218}
}