Method
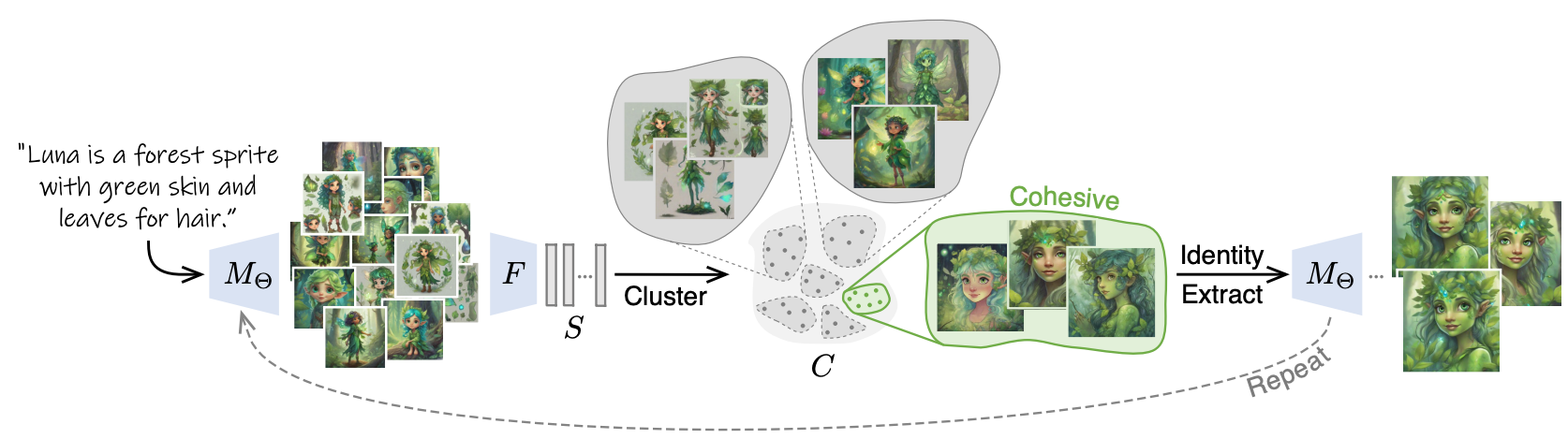
Our fully-automated solution to the task of consistent character generation is based on the assumption that a sufficiently large set of generated images, for a certain prompt, will contain groups of images with shared characteristics. Given such a cluster, one can extract a representation that captures the "common ground" among its images. Repeating the process with this representation, we can increase the consistency among the generated images, while still remaining faithful to the original input prompt.
We start by generating a gallery of images based on the provided text prompt, and embed them in a Euclidean space using a pre-trained feature extractor. Next, we cluster these embeddings, and choose the most cohesive cluster to serve as the input for a personalization method that attempts to extract a consistent identity. We then use the resulting model to generate the next gallery of images, which should exhibit more consistency, while still depicting the input prompt. This process is repeated iteratively until convergence.