Text-to-image model personalization aims to introduce a user-provided concept to the model, allowing its synthesis in diverse contexts. However, current methods primarily focus on the case of learning a single concept from multiple images with variations in backgrounds and poses, and struggle when adapted to a different scenario. In this work, we introduce the task of textual scene decomposition: given a single image of a scene that may contain several concepts, we aim to extract a distinct text token for each concept, enabling fine-grained control over the generated scenes. To this end, we propose augmenting the input image with masks that indicate the presence of target concepts. These masks can be provided by the user or generated automatically by a pre-trained segmentation model. We then present a novel two-phase customization process that optimizes a set of dedicated textual embeddings (handles), as well as the model weights, striking a delicate balance between accurately capturing the concepts and avoiding overfitting. We employ a masked diffusion loss to enable handles to generate their assigned concepts, complemented by a novel loss on cross-attention maps to prevent entanglement. We also introduce union-sampling, a training strategy aimed to improve the ability of combining multiple concepts in generated images. We use several automatic metrics to quantitatively compare our method against several baselines, and further affirm the results using a user study. Finally, we showcase several applications of our method.
Humans have a natural ability to decompose complex scenes into their constituent parts and envision them in diverse contexts. For instance, given a photo of a ceramic artwork depicting a creature seated on a bowl, one can effortlessly imagine the same creature in a variety of different poses and locations, or envision the same bowl in a new setting. However, today's generative models struggle when confronted with this type of task.
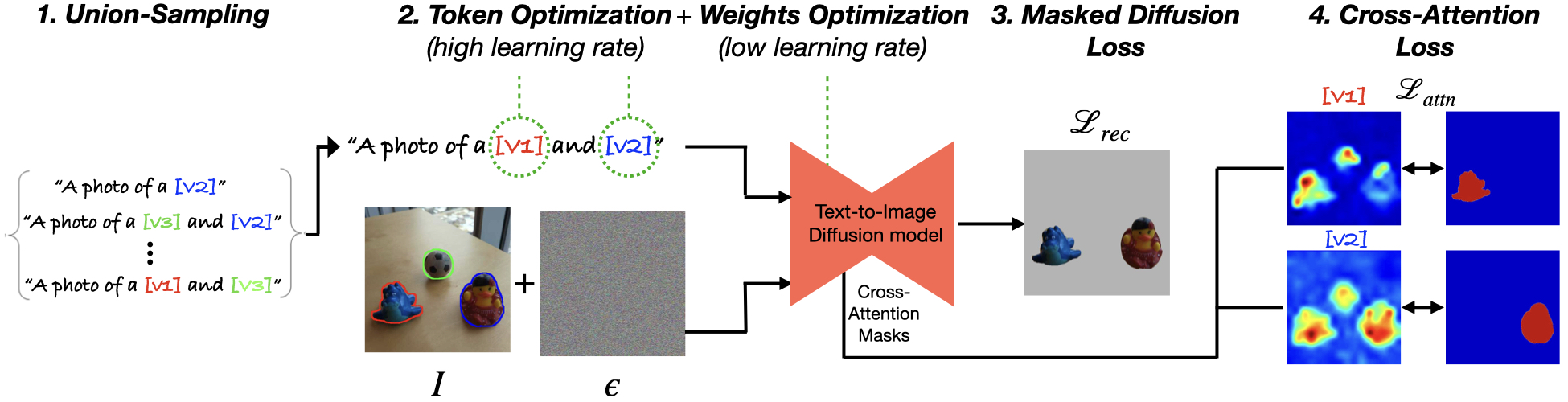
In this work, we propose a novel customization pipeline that effectively balances the preservation of learned concept identity with the avoidance of overfitting. Our pipeline, depicted above, consists of two phases. In the first phase, we designate a set of dedicated text tokens (handles), freeze the model weights, and optimize the handles to reconstruct the input image. In the second phase, we switch to fine-tuning the model weights, while continuing to optimize the handles.
We also recognize that in order to generate images exhibiting combinations of concepts, the customization process cannot be carried out separately for each concept. This observation leads us to introduce union-sampling, a training strategy that addresses this requirement and enhances the generation of concept combinations.
A crucial focus of our approach is on disentangled concept extraction, i.e., ensuring that each handle is associated with only a single target concept. To achieve this, we employ a masked version of the standard diffusion loss, which guarantees that each custom handle can generate its designated concept; however, this loss does not penalize the model for associating a handle with multiple concepts. Our main insight is that we can penalize such entanglement by additionally imposing a loss on the cross-attention maps, known to correlate with the scene layout. This additional loss ensures that each handle attends only to the areas covered by its target concept.
Here are some results of scene breaking and re-synthesis in different contexts and combinations:

Input scene

"A photo of on a solid background"

"A photo of on a solid background"

"A photo of on a solid background"
"A photo of "

"A photo of and its child at the beach"

"A photo of sitting on an avocado in the desert"

"A photo of sitting on an avocado at "

"A photo of on the road"

"A photo of at "

"A photo of a pile of in a straw basket near the Eiffel Tower"

"A photo of a pile of in a straw basket at "

"A photo of sleeping inside in the snow"

"A photo of and at Times Square"

"A painting of inside "

"A photo of and and with flowers in the background"

"A photo of a grumpy cat at "

"A photo of a small albino porcupine at "
Our method is also capable of breaking entangled scenes:

Input scene

"a photo of on a solid background"

"a photo of on a solid background"
"a photo of "

"a photo of a cat wearing in the forest"

"a photo of a running near Stonehenge"

Input scene

"a photo of on a solid background"

"a photo of on a solid background"

"a photo of on a table"

"a photo of swimming"

"a photo of a Labrador wearing "

"a photo of a lion wearing "

"a photo of wearing at the beach"

"a photo of a pig wearing and "

"a photo of wearing and on a wooden floor"

Input scene

"a photo of on a solid background"
"a photo of on a solid background"

"a photo of on a solid background"

"a photo of taking a selfie in the desert"

"a photo of a Moai statue wearing "

"a photo of a parrot wearing "

"a photo of and in the snow"

"a photo of wearing near a lake"

"a photo of an owl wearing and "
Our incorporate our method with Blended Latent Diffusion to achieve local image editing by example:

Input scene

Input image to edit

"a painting of eating a burger"

"a painting of "

Edit result

Input scene

Input image to edit

"a photo of "

"a photo of "

"a photo of "

Edit result

Input scene

Input image to edit

"a photo of "

"a photo of "

"a photo of "

Edit result

Input scene

Input image to edit

"a photo of "

"a photo of "

"a photo of "

Edit result
Our method is also capable of extracting the background of a scene for further edits:

Input scene
"a photo of "

"a photo of a car at "

"a photo of an elephant at "

"a photo of a lighthouse at "

"a photo of a house at "
Given a single image containing multiple concepts of interest, once these are extracted using our method, they can be used to generate multiple variations of the image. The arrangement of the objects in the scene, as well as the background, are different in each generation.

Input scene

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "
Input scene

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "
Input scene

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "
Input scene

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "

"a photo of and and "
If you find this project useful for your research, please cite the following:
@inproceedings{avrahami2023bas,
author = {Avrahami, Omri and Aberman, Kfir and Fried, Ohad and Cohen-Or, Daniel and Lischinski, Dani},
title = {Break-A-Scene: Extracting Multiple Concepts from a Single Image},
year = {2023},
isbn = {9798400703157},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3610548.3618154},
doi = {10.1145/3610548.3618154},
booktitle = {SIGGRAPH Asia 2023 Conference Papers},
articleno = {96},
numpages = {12},
keywords = {textual inversion, multiple concept extraction, personalization},
location = {, Sydney , NSW , Australia , },
series = {SA '23}
}