Aleph 2.0: An upgrade to Runway's flagship video editing model
Runway, 2026
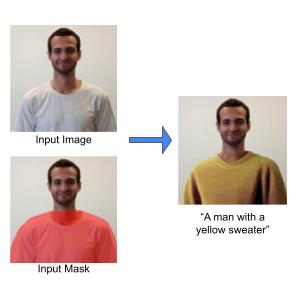
Aleph 2.0 introduces several new and updated model capabilities: working with up to 30 seconds of 1080p video, localized edits with precise input video preservation, image-level control over video edits, and editing across multiple shots at once.